





 xcliang
2024-01-04 16:50
xcliang
2024-01-04 16:50
 举报
举报
 1730
1730
 4
4
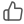

公司拿到的是Knight1.2版本, NPU推理后得到的是定点结果, 后续流程需要将结果转为浮点。通过与清微技术支持人员交流,有以下几种方式可以将结果转为浮点,总结于此, 希望对其它用户有所借鉴。
反量化最本质的原理是将定点结果乘以其对应的反量化系数即可得到浮点结果。为此有2种方式:
方式1:手动方式
假设定点结果为 Tensor output, 模型输出blob为outpublob, 其反量化系数为scale,
则在Python编程中可以如下:
output = output * scale
在C编程中如下(视具体输出层算子类型略有不同,此处假设输出结果类型为s8):
for (int i = 0; i < outpublob->s32N*outpublob->s32H*outpublob->s32W*outpublob->s32C) {
output[i] = output[i] * scale;
}
那么如何得到反量化系数呢?
也有2种方式:
方式1: 使用Netron打开量化后模型查看输出层节点属性, top_scale即为该输出节点的反量化系数, output_bit即为该输出节点的定点输出类型。
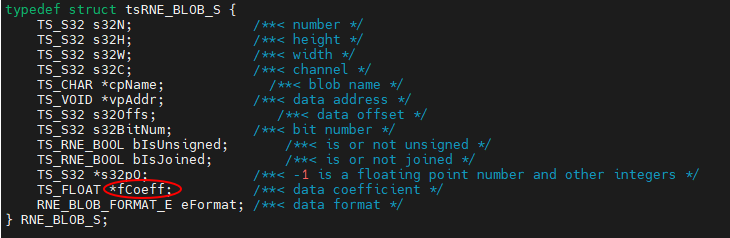
方式2:通过SDK outblob->fCoeff结构体成员获取, 此方式在实际部署中比较方便,可以根据模型资源自动变化。(但1.2版本似乎有些小bug,个别模型的不正确)
方式2:自动方式
通过在ONNX量化时启用'-od'参数, 量化后模型会自动增加反量化层, 模型输出自动为浮点。不过此方式1.2版本只在量化时实现了,后面的编译、模拟、SDK中还没完全打通,希望后续版本能够全打通。这样刚开始移植模型时就比较方便了。


























































 Flower官方
2024-01-04 17:14
Flower官方
2024-01-04 17:14
 回复
回复

 管理员
2024-01-04 17:03
回复
管理员
2024-01-04 17:03
回复
 xcliang 回复 管理员
2024-01-04 17:04
回复
xcliang 回复 管理员
2024-01-04 17:04
回复
 Flower
Flower
 京公网安备 11010802041762号
京公网安备 11010802041762号